
A Three-Layer Framework for AI Research That Actually Works
Here's a structured approach for Product Marketers to prevent hallucinations and deliver insights you can trust.
Picture this: You've just wrapped up 20 customer interviews. You're buried deep in transcripts, trying to mine them to extract insights to leadership and the product team. You think, "Why don’t I drop everything into ChatGPT and see what it finds? It’s good at summarizing, right?"
So you upload the transcripts, ask "what are the key themes?" and within seconds, you get back a beautifully formatted summary with clear insights, proper categorization, and articulate recommendations. It reads well. It sounds right. You're sure the product team will love it.
There's just one problem: It's not quite what your customers actually said.
This is the AI research trap that product marketers are falling into right now. The output looks polished. The insights sound reasonable. But somewhere between your raw data and the final summary, the fidelity got lost. Details shifted. Connections appeared that weren't quite there in the original conversations. Language changed and you're stuck mining the document to identify variations. It’s not easy to spot the inconsistency. So all that time you thought you were saving, is actually now spent in review.
As a Product Marketing you know that when teams are making product decisions based on customer insights, "close enough" isn't good enough.
But here's what's frustrating: AI genuinely can process more customer data than any human team, at a scale that was impossible before. The opportunity to synthesize insights across sales calls, support tickets, user interviews, and market research—all in one coherent narrative—is real! We're just approaching it wrong.
Brian Greene, a fractional research leader who builds AI practices for companies, has spent the past year solving this problem. His answer? Stop treating AI like a conversation partner. Start treating it like a system that needs architecture.
Why Your Current Approach Isn’t Working
The Hallucination Problem
Greene is clear about what's happening when you dump data into an LLM without structure: "An out of the box LLM that you just drop large amounts of information into, will hallucinate. It will at a minimum paraphrase."
The reason comes down to what LLMs are actually built to do. As Greene explains it, "An LLM is meant to be helpful, it's meant to be cohesive about returning the sort of probabilistic set of information that matches what you're looking for. It's not meant to be 100% accurate, like full fidelity of what's happening."
This is the fundamental tension. Helpfulness and accuracy aren't the same thing. An LLM will fill in logical gaps, and present information in a way that feels coherent, even when that means sacrificing the precise details that matter most for research.
When it paraphrases a customer quote, it might capture the general sentiment while missing the specific language that reveals the underlying need. Filling in gaps between two data points can create a connection that sounds logical but doesn't reflect reality. The risk is that it takes it too far in another direction and misses the nuance a human researcher would catch.
Of course, the output looks so polished that it's easy to trust. There are no obvious red flags or indications that what you're reading might not be fully accurate, so the researcher needs to invest energy in reviewing the output very carefully.
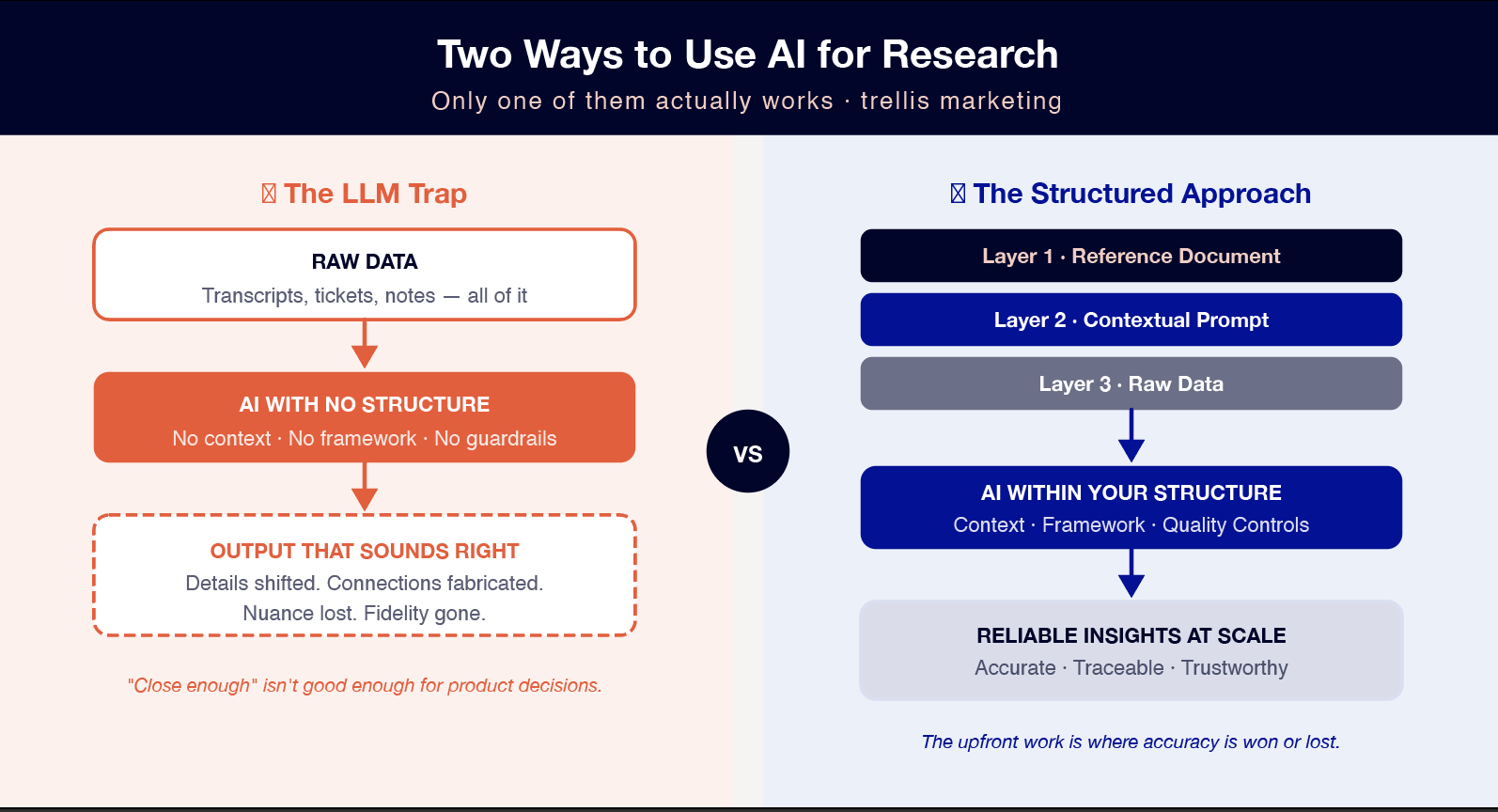
The LLM Trap
Greene sees one approach as particularly risky: "If you're just dumping into ChatGPT, for example, that's probably the most risky as you're not providing the context. It may not have the files you're referring back to."
This is what I call the LLM trap—the temptation to treat AI like a colleague who you hand a pile of research to and say "tell me what this means." The interface encourages this behavior. As a large language model, they’re designed to feel conversational and convenient.
But here's what's missing. ChatGPT, for example, doesn't know your product. It doesn't know your market. It doesn't know how you categorize customer problems or what framework you use to prioritize insights. So it makes educated guesses and those guesses are baked into the output you're getting back.

What We're Really Solving For
Before we get too critical of AI's current limitations, Greene offers an important reminder: "The typical process we did with human synthesis and review wasn’t always 100% accurate."
Manual research synthesis has always been imperfect. One analyst might categorize a customer problem differently than another. Human bias creeps in. We get tired. We miss patterns because we're processing information sequentially rather than holistically. And most critically, we simply can't process the volume of data that modern companies generate.
This is where Greene sees the real opportunity: "One of the big opportunities is scaling insights and enabling people to leverage that in their day to day decision making."
Previously, organizations struggled to think holistically. User research lived in one place, market research in another, support data in a third. Sales insights rarely made it back to the product team, or when it did, it wasn’t immediate but rather weeks or months after the feedback was received. The effort required to stitch together these distinct sources of information was massive, so most companies simply didn't do it well, or fast enough.
AI changes the economics of this entirely. As Greene points out, "AI is really good at ingesting large amounts of data and making sense of it." The question is how to harness that capability while avoiding the accuracy problems.
The answer is structure.
"The full Three-Layer Framework — including the exact prompt structure and two safeguards most teams skip — is below. Enter your email to keep reading."
The Three-Layer Framework
Greene's approach is built on one core principle: "You must create a structured approach."
This isn't about finding the right prompt or the right AI tool. Structure is what determines whether AI research is useful or dangerous. The planning phase, the time before you ever feed data into an LLM, is where accuracy is won or lost.
The framework has three layers, each serving a specific purpose in the system. Think of it less like a conversation and more like a data pipeline that you're architecting.
Layer 1: The Structured Reference Document
The first layer is what Greene calls "the static reference"—a structured document that provides the context an LLM doesn't have.
“Create a structured document that gives the definition of what all of the inputs are, explain what they are, and give a set of examples.”
Let's break down what this actually means in practice.
Definitions: These are the specific terms and concepts unique to your product and market. If you categorize customer problems as "workflow friction," "integration gaps," or "visibility issues," you need to define exactly what each of these means. Not in general terms—in the specific context of your product.
Explanations: This is your framework for how you think about the research. How do you prioritize pain points? What distinguishes a feature request from an underlying need? What's your mental model for categorizing different types of customers? All of this needs to be explicit.
Examples: This is where the critical work happens. For each category, provide concrete examples of what belongs there. If you're looking for pain points related to workflow friction, show the LLM what an actual customer quote about workflow friction looks like. Show it what a quote that seems like workflow friction but is actually something else looks like. Show it edge cases.
The reason this matters: LLMs are very good at understanding intention and matching patterns. But they need clear patterns to match against. Your reference document creates those patterns.
The upfront work is additional but this is where accuracy comes from.
Layer 2: The Contextual Prompt
The reference document tells the AI what things mean. The prompt tells it what to do.
This is the instruction layer—the logic that governs how your structured reference document gets applied to incoming data. As Greene describes it:
“Then you have the prompt that will say here’s how to use this set of data, of examples, and the structure you want.”
Your prompt needs to specify several things:
Application instructions: How should the AI match incoming data against your reference document? Should it assign each piece of feedback to a single category or allow multiple categories? Should it extract specific quotes or summarize themes?
Handling exceptions: What happens when something doesn't fit your framework? Greene's answer: "If something falls outside of this, you can flag that as an alternative." Your prompt should explicitly tell the AI to flag anything that doesn't clearly match your defined categories rather than forcing it into the closest approximation.
Output format: Be specific about what you want back. If you want a table with columns for customer quote, category, and confidence level, say that. If you want a ranked list of themes with supporting evidence, specify the exact structure.
The prompt is also where you build in quality controls. You can instruct the AI to provide its reasoning for each categorization. You can ask it to highlight any places where it's uncertain. You can tell it to preserve exact quotes rather than paraphrasing when pulling supporting evidence.
Here's an example of what a simple prompt might look like:
"Using the framework and examples provided in the reference document, analyze the following customer interview transcript. For each distinct pain point or need mentioned:
Assign it to one of the defined categories, or flag it as 'uncategorized' if it doesn't clearly fit
Extract the exact customer quote (do not paraphrase)
Note your confidence level (high/medium/low) based on how well it matches the examples
If confidence is medium or low, explain why
Return results in a table format."
The specificity matters. Vague prompts get you vague (and often inaccurate) results. Clear instructions, combined with your structured reference document, give the AI guardrails that keep it accurate.
Layer 3: Raw Data Application
This is where your system actually runs. The raw data—customer interview transcripts, support tickets, sales call notes, survey responses—flows through the structure you've built.
The beauty of this three-layer system is that each piece has a distinct job. Your reference document provides the context and patterns. Your prompt provides the instructions and quality controls. The raw data is just data—it doesn't need to be cleaned up or pre-processed in ways that might introduce bias.
The AI takes your raw data and runs it against your framework. When something matches clearly, it gets categorized. When something doesn't fit, it gets flagged. When the AI is uncertain, it surfaces that uncertainty rather than making a confident-sounding guess.
This is where most people get it wrong. They expect the AI to figure out the framework from the data itself. But that's backwards. The framework needs to exist first, built from your domain expertise and understanding of your market. The AI's job is to apply that framework at scale.
Greene's assessment of what happens when you get this right: "When you get good at creating the structured approach, you can get good accuracy from LLMs. You just need to know how to do it and spend the time upfront."
That's the trade-off. More upfront work. Better accuracy. The question is whether you're willing to invest in the planning phase to get reliable insights at the scale AI enables.
The Three Layer Framework for AI Research
Practical Implementation: Moving from Chatting to Building a Real System
Greene makes a distinction that matters: "If you go one step further from say ChatGPT to Claude Code, and you move from adding data in and chatting to moving to building a structured framework."
The shift is from conversational AI to systematic AI. You're not having a dialogue. You're building infrastructure.
His approach:
Build a project with a specific set of context.
Set up an organizing document that explains what's happening inside of this.
Set up references to all the data sources and I'll be able to query it.
With tools like Claude Code, you can create a local directory on your computer. Drop in all your transcripts and data sources. Add your organizing documents—your reference framework, your prompts, your structure. Then query against the whole system.
The difference is that the AI isn't improvising. It's operating within the parameters you've defined, with access to all the context you've provided, following the specific instructions you've built into your prompts.
What AI Should Actually Do For You
Greene is clear about his philosophy on this: He wouldn't use an LLM to tell him what he learned from a study.
Instead, he uses AI for "helping to process more data than we could before, at a larger scale."
The practical applications:
Pulling together data to write a narrative
Getting help to write SQL queries to analyze data
Creating data pipelines to automate the ingestion and synthesis of information on a continuous basis
Greene is clear that the pre-work is critical. When a PMM or PM and a researcher talk to a bunch of customers or prospects and they’re putting call summaries into the LLM and thinking, what can it do that we can't? You must do the pre-work to really figure this out. The research planning phase is where the value gets created. AI execution is just applying that plan at scale. It’s tempting to skip but you’ll pay the price later.
The Product Marketer's Unique Advantage
There's an organizational reality that Greene sees clearly: Research teams are stretched thin. User research and market research often live in different silos. There are always more PMMs than researchers. For early stage companies, there may only be a PMM and no research team.
But "From a customer point of view, the data and insights source doesn't matter. The customer journey is one journey."
Greene sees that PMMs have the opportunity to collaborate with research to pull these all together into one cohesive narrative and share back to advocate for the customer needs.
This is where AI becomes a force multiplier. Not by replacing researchers, but by giving teams the ability to process and synthesize data across all these sources at a scale that was previously impossible.
The Lost Opportunity Problem
But there's a catch. As Greene points out, product marketing and research "are not staffed the same way as other teams and are stretched thin."
The result? "You can have all of this data but if people don't know about it..…it's a lost opportunity."
AI can help process the data. But it can't solve the organizational problems of data silos, insights not being shared, or stakeholders not being aligned. Those remain human problems that require human solutions.
The Dangers of Getting This Wrong
What Happens Without the Right Structure and Human Connection
Greene is direct about the risks: "If you don't have the right plan. The right organization. The context. The output will not be helpful."
But the bigger danger is more subtle. It's about what gets lost when we rely too heavily on AI without understanding its limitations.
His example: "You could say here are the company principles and a human may say, no one really cares about principle 1 and 2. AI will say these are the principles and that's that. It doesn't capture nuance."
This is the risk of losing human connection, losing the ability to read between the lines, losing critical thinking. AI takes things literally. It doesn't understand organizational politics, unspoken priorities, or the gap between what people say and what they mean.
Greene's warning: "There's all this potential but if organizations are not supporting research orgs and teams, and thinking AI can do it all, they increase the risk of these errors."
The Other Extreme
But Greene sees danger on the other side too: "If you think that AI is the worst thing ever and want to keep your head in the sand, well I think we all know that life is going to pass you by."
His philosophy: "AI is a tool and like with any tool, if you use it right, it can be extremely powerful but if orgs think, this is going to solve everything, it could be really bad."
The middle path is understanding what AI is good at (processing large amounts of data, finding patterns, applying frameworks at scale) and what it's not good at (capturing nuance, understanding context, exercising judgment about what matters).
What's Coming Next: Greene's Predictions
We're at a change point. Greene expects lines between roles will blur more. “For example a product marketer or researcher can vibe code a functional prototype for research, moving more into the PM domain."
This isn't about replacing roles. It's about democratizing execution. A product marketer might code a prototype that would never ship to production, but that prototype enables deeper research insights. A researcher might fix bugs or work on design. Everyone becomes "closer to building than we were in the past."
For research specifically, Greene is "hopeful that research will be able to be more holistic and have a deeper connection to qualitative and quantitative data than we had in the past. While still retaining the ability to stitch insights together to understand what it means for the business."
The Operations Challenge
One prediction stands out: "Operations and the orchestration of operations is going to be more important than ever."
The questions that will matter: "How do you weave the insights, make sense of them, distribute them. Make a research repository, which is often an unrealized goal for companies."
AI makes it possible to process insights at scale. But someone still needs to orchestrate how those insights flow through the organization, how they get synthesized, how they reach the right people at the right time.
That orchestration work—the human work of making sense of data and turning it into strategy—becomes more valuable, not less.
Your Next Steps
Start With One Use Case
Don't try to build a comprehensive AI research system overnight. Pick one recurring task where you're already processing customer data manually.
Maybe it's synthesizing monthly customer calls or categorizing support tickets. Maybe it's pulling themes from sales conversations.
Start there.
Build Three Layer Framework (Plus Two Essential Safeguards)
Design phase:
Structured Reference Document: Create your structured reference document. Define your terms. Explain your framework. Provide examples of what belongs in each category and what doesn't.
Contextual Prompt: Write your prompt. Be specific about how the AI should apply your framework. Tell it what to do with exceptions. Define your output format.
Raw Data Application: Feed in your raw data and see what happens. Look at what gets flagged. Look at where the AI is uncertain. Use that feedback to refine your reference document and your prompt.
Two Critical Safeguards
The three layers outlined above will prevent hallucinations at the design stage but when running this at scale, you need to add two additional safeguards to ensure you can trust the output.
Safeguard 1: Traceability
It’s critical that you can verify what the AI is telling you against the source.
Example: When the AI model flags ‘workflow friction’ in a customer quote, you should be able to click through to see the exact transcript,
Why this matters: This allows you to understand why it was categorized that way and verify the categorization, improving trust in the output.
Safeguard 2: Staged Processing
Preserve the data you have at each different stage.
Example: Instead of going from the interview transcript to the final insight, you save a record of the original transcript, then you save separately the AI categorization, and finally you save the synthesized themes separately.
Why this matters: Allows you to easily audit any stage, re-run different stages as you refine the framework, and more easily catch errors.
It’s important to realize that the system gets better with iteration. Your first pass won't be perfect. That's expected.

The steps to build an accurate AI informed research system
The Real Goal
This framework isn't about replacing your judgment with AI. It's about processing more signals than you could before, so you can spend your time on your true value PMMs deliver: understanding what the insights mean, building the narrative, and driving strategy.
Greene's closing thought applies here: The planning phase is critical. The upfront work determines whether AI research is a liability or an advantage.
Most product marketers will keep leaning on LLMs, inputting the data into ChatGPT and wondering why the insights feel off. The ones who take the time to build the structure and invest in building the system properly—will deliver accurate customer insights at scale.
Brian Greene is a fractional research leader who helps companies build AI-powered research practices. With deep expertise at the intersection of qualitative research, product strategy, and emerging AI tooling, he works with organizations to design structured systems that scale customer insights without sacrificing accuracy. Brian works with product, marketing, and research teams navigating the shift to AI-assisted decision making.
At Trellis Marketing, we help product marketers navigate these strategic shifts. Building the skills, frameworks, and confidence to become indispensable strategic partners in an AI world. If you're ready to level up your research and insight synthesis practice, let's talk.